Reinforcement Learning là gì?
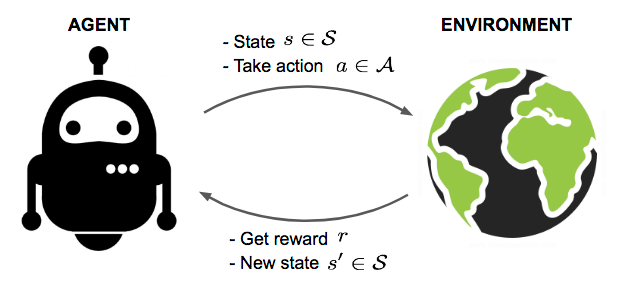
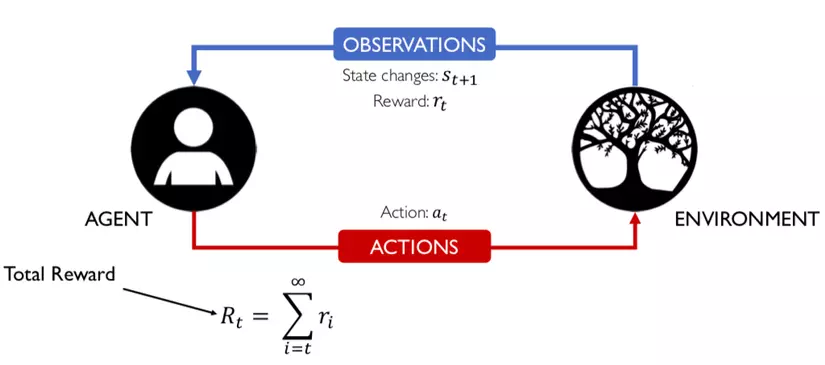
Fig. 1. An agent interacts with the environment, trying to take smart actions to maximize cumulative rewards.
Giả sử, chúng tôi có một đại lý trong một môi trường không xác định và đại lý này có thể nhận được một số phần thưởng bằng cách tương tác với môi trường. Người đại diện phải thực hiện các hành động để tối đa hóa phần thưởng tích lũy. Trong thực tế, kịch bản có thể là một bot chơi trò chơi để đạt được điểm số cao, hoặc một robot cố gắng hoàn thành các nhiệm vụ vật lý với các vật phẩm vật lý; và không chỉ giới hạn ở những thứ này.
Bạn đã bao giờ trách móc hoặc đánh đập con chó của mình một cách nghiêm khắc vì những hành động sai trái sau khi nó làm chưa? Hay bạn đã bao giờ huấn luyện một con vật cưng và thưởng nó cho mỗi lệnh đúng mà bạn yêu cầu chưa? Nếu bạn là chủ sở hữu vật nuôi, có lẽ câu trả lời của bạn sẽ là ‘Có’. Bạn có thể nhận thấy một khi bạn làm như vậy thường xuyên từ khi nó còn nhỏ, những việc làm sai trái của nó giảm dần từng ngày. Và cũng giống như nó sẽ học hỏi từ những sai lầm và rèn luyện bản thân thật tốt.
Là con người, chúng ta cũng đã từng trải qua điều tương tự. Bạn có nhớ không, ở trường tiểu học của chúng tôi, các giáo viên của trường chúng tôi đã thưởng cho chúng tôi những ngôi sao khi chúng tôi đã hoàn thành tốt các công việc của trường. Đây chính xác là những gì đang xảy ra trong "Học tăng cường" (RL).
Reinforcement Learning is one of the most beautiful branches in Artificial Intelligence
Mục tiêu của RL là tìm kiếm một chiến lược tốt cho "chủ thể" từ các "trải nghiệm" và nhận được phản hồi từ những tương tác với môi trường. Với chiến lược tối ưu, chủ thể có khả năng chủ động thích ứng với môi trường để tối đa hóa phần thưởng trong tương lai.
Các khái niệm chính trong RL
Chủ thể (agent) đang hoạt động trong môi trường (environment). Cách môi trường phản ứng với các hành động nhất định được xác định bởi một mô hình (model) mà chúng ta có thể biết hoặc có thể không biết. Chủ thể (agent) là người đưa ra quyết định (make a decision), có thể ở một trong nhiều trạng thái (states) (s ∈ S) của môi trường, và chọn thực hiện một trong nhiều hành động (actions) (a ∈ A) để chuyển từ trạng thái này sang trạng thái khác. Trạng thái nào mà chủ thể sẽ có được quyết định bởi xác suất (probabilities) chuyển đổi giữa các trạng thái (P). Khi một hành động được thực hiện, môi trường mang lại phần thưởng (reward) (r ∈ R) dưới dạng phản hồi.
RL là khoa học về việc đưa ra các quyết định tối ưu bằng cách sử dụng kinh nghiệm. Chi tiết hơn, quá trình RL bao gồm các bước đơn giản sau:
2. Quyết định cách hành động bằng một số chiến lược (Decision)
3. Hành động phù hợp (Action)
4. Nhận phần thưởng hoặc hình phạt (reward/penalty)
5. Học hỏi kinh nghiệm và hoàn thiện chiến lược của chúng tôi (Learn)
6. Lặp lại cho đến khi tìm được chiến lược tối ưu
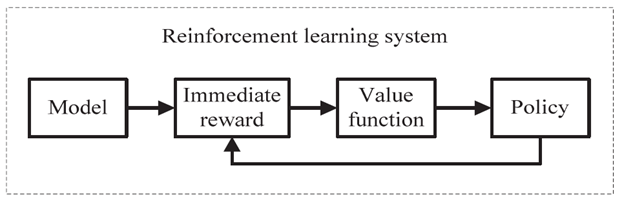 Mô hình hóa toán học của RL
Mô hình hóa toán học của RL1. Đây là một ví dụ trực quan về Agent:
2. Enviroment xung quang của Agent, nơi mà agent tồn tại và tương tác:
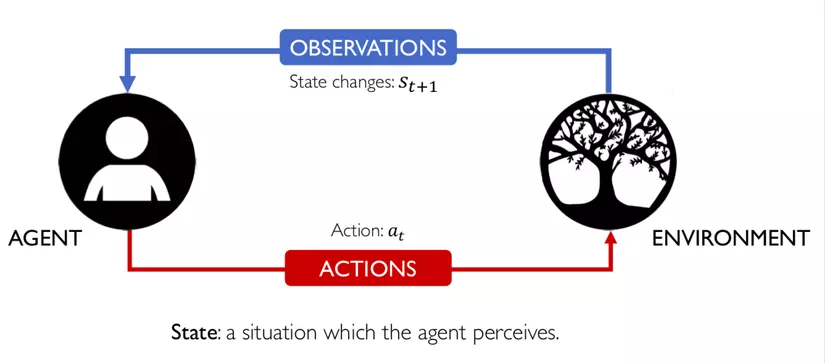
3. Dựa trên State S(t) của enviroment hiện tại mà agent sẽ đưa ra action a(t):
4. Sau khi nhận được sự tương tác từ agent thì enviroment có sự chuyển đổi trạng thái đối với agent:
5. State lúc này của enviroment là S(t+1), tức ở thời điểm t+1:
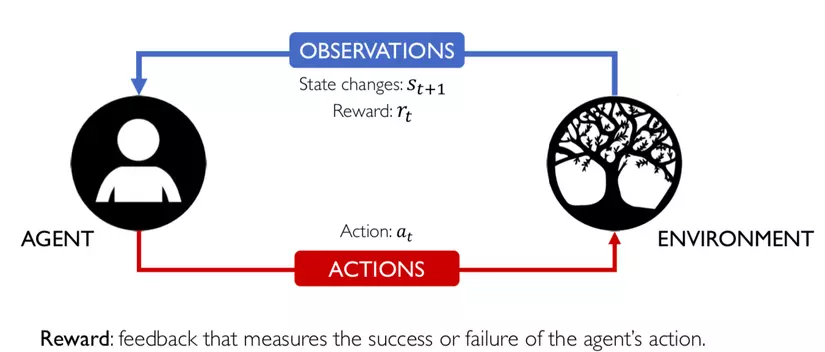
6. Lúc này, agent nhận được reward r(t). Reward này phụ thuộc vào action a(t) của agent và State S(t) của enviroment ở thời điểm trước đó, tức là ở thời điểm t:
7. Vì ta không biết thời điểm kết thúc của sự lặp đi lặp lại này nên tổng reward sẽ là một chuỗi vô hạn của các reward thành phần tại các thời điểm khác nhau kể từ thời điểm t (lúc đầu):
8. Chúng ta có thể khai triển chuỗi vô hạn này như sau:
9. Vì chuỗi này không thể nào hội tụ (convergence) được nên trên thực tế các nhà nghiên cứu có thể dùng một cái trick để chuỗi này có thể hội tụ được. Như hình dưới đây, họ đưa vào thêm một term thường được gọi là discount factor (discount rate) để làm cho chuỗi này hội tụ.
Lưu ý việc hội tụ là bắt buộc nếu bạn muốn train thành công một agent nói riêng hay một mạng Neural Network nào đó nói chung.
Tất cả những thứ trên nó dựa trên một framework được gọi là Markov Decision Processes (MDPs). Về cơ bản thì một MDP cung cấp một framework toán học cho việc modelling các tình huống decision-making. Ở đây, các kết quả (outcomes) xảy ra một cách ngẫu nhiên một phần và phần còn lại thì phụ thuộc trên các action của agent (hoặc decision maker) đã tạo ra trước đó. reward thu được bởi decision maker phụ thuộc trên action mà decision maker chọn và dựa trên cả hai State mới (S(t+1)) và cũ (S(t)) của enviroment.
Để có thể train được agent thì mục tiêu của chúng ta là phải tìm được policy sao cho:
* là discount factor và < 1
Về cơ bản thì chúng ta đang cố gắng để maximize tổng của tất cả các reward (có tính đến discount factor như đã đề cập ở trên) ở mỗi state cụ thể từ lúc bắt đầu đến khi kết thúc (dẫu cho T tiến về vô cùng, vì chúng ta chưa biết khi nào thì quá trình này kết thúc nên nó vẫn luôn là một chuỗi vô hạn), và đương nhiên là phải dựa trên policy vì agent của chúng ta base trên nó để chọn reward tốt nhất mà. Bản chất thì đây là một bài toán tối ưu (optimazation problem).
Ở trên là một tiêu chí mà chúng ta có thể dùng để optimize cho việc tìm ra nghiệm (optimal policy). Cụ thể chúng ta gọi tiêu chí này là infinite horizon sum reward criteria. Phụ thuộc vào các criteria khác nhau mà chúng ta sẽ có các algorithm khác nhau để tìm ra optimal policy. Với infinite horizon sum reward criteria thì chúng ta có thể sử dụng một thuật toán RL cũng khá kinh điển đó là Q-Learning để giải quyết, tôi sẽ giới thiệu trong bài viết tiếp theo.
Agent:



State S(t) của enviroment hiện tại mà agent sẽ đưa ra action a(t):

agent thì enviroment có sự chuyển đổi trạng thái đối với agent:

State lúc này của enviroment là S(t+1), tức ở thời điểm t+1:
reward r(t). Reward này phụ thuộc vào action a(t) của agent và State S(t) của enviroment ở thời điểm trước đó, tức là ở thời điểm t:
reward sẽ là một chuỗi vô hạn của các reward thành phần tại các thời điểm khác nhau kể từ thời điểm t (lúc đầu):


action của agent (hoặc decision maker) đã tạo ra trước đó. reward thu được bởi decision maker phụ thuộc trên action mà decision maker chọn và dựa trên cả hai State mới (S(t+1)) và cũ (S(t)) của enviroment.Để có thể train được agent thì mục tiêu của chúng ta là phải tìm được policy sao cho:
* là discount factor và < 1
reward (có tính đến discount factor như đã đề cập ở trên) ở mỗi state cụ thể từ lúc bắt đầu đến khi kết thúc (dẫu cho T tiến về vô cùng, vì chúng ta chưa biết khi nào thì quá trình này kết thúc nên nó vẫn luôn là một chuỗi vô hạn), và đương nhiên là phải dựa trên policy vì agent của chúng ta base trên nó để chọn reward tốt nhất mà. Bản chất thì đây là một bài toán tối ưu (optimazation problem).Ở trên là một tiêu chí mà chúng ta có thể dùng để optimize cho việc tìm ra nghiệm (optimal policy). Cụ thể chúng ta gọi tiêu chí này là infinite horizon sum reward criteria. Phụ thuộc vào các criteria khác nhau mà chúng ta sẽ có các algorithm khác nhau để tìm ra optimal policy. Với infinite horizon sum reward criteria thì chúng ta có thể sử dụng một thuật toán RL cũng khá kinh điển đó là Q-Learning để giải quyết, tôi sẽ giới thiệu trong bài viết tiếp theo.
Phân loại các phương án trên RL
Để phân loại rõ ràng các thuật toán trên RL khá phức tạp, chúng ta có thể nhìn hình bên dưới và tạm thời chia theo vài trường hợp chính:
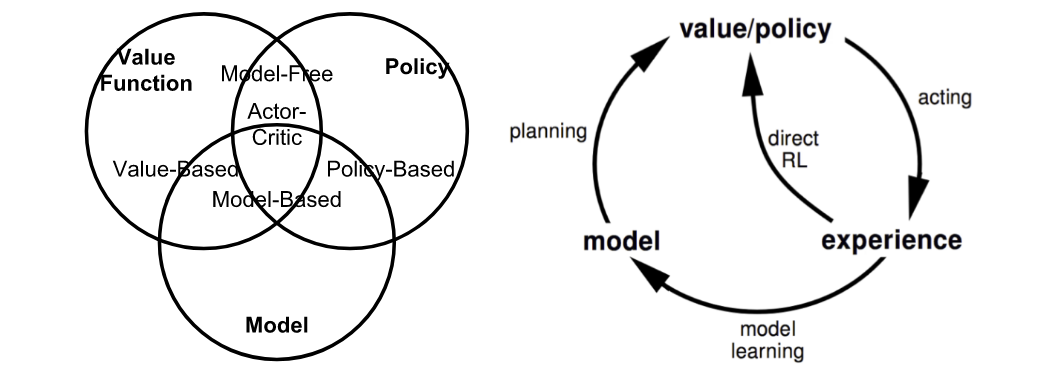
Fig. 2. Summary of approaches in RL based on whether we want to model the value, policy, or the environment. (Image source: reproduced from David Silver’s RL course lecture 1.)
- Model-free: thuật toán ước tính chính sách tối ưu mà không cần sử dụng hoặc ước tính động lực học (chức năng chuyển đổi và phần thưởng) của môi trường.
- Model-based là một thuật toán sử dụng hàm chuyển tiếp (và hàm phần thưởng) để ước tính chính sách tối ưu.
- On-policy: Sử dụng kết quả xác định hoặc mẫu từ chính sách mục tiêu (target policy) để đào tạo (train) thuật toán.
- Off-policy: Đào tạo về cách phân phối các chuyển đổi (transitions) hoặc các tập (episodes) được tạo ra bởi một chính sách (policy) hành vi khác chứ không phải do chính sách mục tiêu tạo ra.
Ngoài ra, nếu nhìn tổng quát hơn ta có thể phân loại Rl thành những nhóm như hình bên dưới

 Tiếp theo, để tạo nền tảng kiến thức vững vàng trước khi đi vào phân tích cũng như phát triển thuật toán trên RL các bạn nên tìm đọc và hiểu về cách khái niệm như Trasition, Reward, Policy, Value Function,... đặc biệt là Markov Decision Processes và Bellman Equations (có thời gian mình sẽ phân tích thêm về phần này) từ sách.
Tiếp theo, để tạo nền tảng kiến thức vững vàng trước khi đi vào phân tích cũng như phát triển thuật toán trên RL các bạn nên tìm đọc và hiểu về cách khái niệm như Trasition, Reward, Policy, Value Function,... đặc biệt là Markov Decision Processes và Bellman Equations (có thời gian mình sẽ phân tích thêm về phần này) từ sách. Ví dụ
Reinforcement Learning: An introduction (link)
Hoặc tổng hợp khác của tôi ở đây
P/s: từ tài liệu tiếng anh có nhiều từ rất khó để dịch sát nghĩa sang tiếng việt nên khó tránh khỏi sai sót, nhưng vì mong muốn các bạn ở VN có nhiều nguồn tài liệu để tiếp cận hơn. Các bạn có khả năng đọc hiểu tiếng anh thì nên đọc sách góc sẽ tốt hơn. Các phần tiếp theo mình đã xử lý dưới xong rồi, mình có thời gian sẽ tiếp tục, kết hợp với code mô phỏng. Hy vọng các bạn tìm thấy được sự thú vị từ đây! have fun 😏
Để phân loại rõ ràng các thuật toán trên RL khá phức tạp, chúng ta có thể nhìn hình bên dưới và tạm thời chia theo vài trường hợp chính:
- Model-free: thuật toán ước tính chính sách tối ưu mà không cần sử dụng hoặc ước tính động lực học (chức năng chuyển đổi và phần thưởng) của môi trường.
- Model-based là một thuật toán sử dụng hàm chuyển tiếp (và hàm phần thưởng) để ước tính chính sách tối ưu.
- On-policy: Sử dụng kết quả xác định hoặc mẫu từ chính sách mục tiêu (target policy) để đào tạo (train) thuật toán.
- Off-policy: Đào tạo về cách phân phối các chuyển đổi (transitions) hoặc các tập (episodes) được tạo ra bởi một chính sách (policy) hành vi khác chứ không phải do chính sách mục tiêu tạo ra.
Ví dụ
Reinforcement Learning: An introduction (link)
Hoặc tổng hợp khác của tôi ở đây
P/s: từ tài liệu tiếng anh có nhiều từ rất khó để dịch sát nghĩa sang tiếng việt nên khó tránh khỏi sai sót, nhưng vì mong muốn các bạn ở VN có nhiều nguồn tài liệu để tiếp cận hơn. Các bạn có khả năng đọc hiểu tiếng anh thì nên đọc sách góc sẽ tốt hơn. Các phần tiếp theo mình đã xử lý dưới xong rồi, mình có thời gian sẽ tiếp tục, kết hợp với code mô phỏng. Hy vọng các bạn tìm thấy được sự thú vị từ đây! have fun 😏


![[English] ex viết tắt của từ gì? ex là gì? ex nghĩa là gì?](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhFiRP7spsayG2ppte_20L5qkUrX_HsatNpN8LxoNux1ewEve0IUrCurRVh7VfOvFvrgvnfloMyf_KXZnWfif-BDKLlU5A9zSat0y-Bvu3BeNedpCEJsmMzBTZ-KVRFPfIUZZI60uG8Z5k/s72-c/what-is-ex-meaning.jpg)
![[VI ĐIỀU KHIỂN PIC] - BÀI 6: TIMER/COUNTER CỦA PIC TRONG CCS](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjCz787KDILJfZRV78M_FwKV1KfpbML6oDxg3VEpJgu0t0RJY02ANCf7h2BeqkgD5UgoufjwXLnxGh8Hj1RlBnjlkQYUBrrjUwObg3Ru4lGv0Slpmf1xEjvDJMp5sg425Oaoc_NCuUFqow/s72-c-d/pic-microcontrollers-examples-in-assembly-language-chapter-04-fig4-1.gif)
![[VI ĐIỀU KHIỂN PIC] - BÀI 7: ANALOG (ADC) CỦA PIC TRONG CCS](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiUKGTlRMrOPiQlrL-hvj4au7WA4MEdUChYe_L6bH5mOIDDBpmEBaW_oIKQYz04kfHKY2FmcWb8urcsZgPXMNp5r4ZHqskRjbYNp12JvklYcXHrnweaizv7lKPyribPyxWtsUNzggwXfOI/s72-c/04-06-2017+10-28-24+PM.png)
![[VI ĐIỀU KHIỂN PIC***] - BÀI TẬP MẪU ĐẶC BIỆT CỦA VI ĐIỀU KHIỂN PIC16F877A](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjeSJllTzabiuuA-Zd8LVZY9urJdd-InM0cVOkJtiqrwHcEGJQIajPm7BoERinwbHbEJ2fzFN_P49llQiqF-KyGMuY9NkP5HdA31GAcfcG4WjHdZl2RDngNbMNjts3gpkgib5sVR01eeKc/s72-c/1.png)
![[VI ĐIỀU KHIỂN PIC] - BÀI 9: KHỞI TẠO PWM TRONG PIC 16F877A VỚI CCS](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjerTKUiWHBBUrmBbbOQILAmqhC73Ubt_nYZR9fSu1FCPX2aXz59Ir4kJRIkpphvjOK_Aljt1NCDqHct6fmoeX8JomWvOu06OkZ7fYQvK975ftMf1J4kP8iYpX6P9tPo3NmiSXTS_vUjRY/s72-c/10-06-2017+11-40-42+PM.png)

![[VI ĐIỀU KHIỂN PIC] - BÀI 8: GIAO TIẾP LM35 PIC16F877A TRONG CCS](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgf6kgYQjVzdLTbPiEhjagyXQbubtwplknQ3H2kdg-7T6Di-5_oIpvAGdP3W4DL9sKeSUktz35CKibzHAz7j0eZI5sp1kGnbTYT5bBoy0P7Xv-RPxmUC_SXC9FkrCXS4Kdc3Ob1E7cI0eI/s72-c/HH.png)
![[Research] Cách viết và cấu trúc chi tiết một bài báo khoa học](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiK5FSwIEKPC-QCKmUI_fsFHf3mhlU4GnKEgYQ5vo6SnFVhgOb9iR4_1pCRXk8kuKCQuh9m8xZGH8nDQGO-gsAq5IhT1t5wpHfN3iTLtN45k1UeNG36d1QhMPHPLgpJQntMRPIjb2vwI-0/s72-c/Picture5.jpg)