Bài trước tôi đã giới thiệu về RL và bây giờ tôi sẽ nói về phương pháp đơn giản để chúng ta dễ dàng tiếp cập với RL.

Q-learning là gì?
Q-learning là một thuật toán học tăng cường không có mô hình (Model-free). Nó học tập dựa trên các giá trị (values-based). Các thuật toán dựa trên giá trị cập nhật hàm giá trị dựa trên một phương trình (đặc biệt là phương trình Bellman). Trong khi loại còn lại, dựa trên chính sách (policy-based) ước tính hàm giá trị với một chính sách tham lam có được từ lần cải tiến chính sách cuối cùng.
Q-learning is an off-policy learner
Có nghĩa là nó học được giá trị của chính sách (policy) tối ưu một cách độc lập với các hành động của chủ thể (agent). Mặt khác, on-policy learner tìm hiểu giá trị của chính sách đang được thực hiện bởi chủ thể, bao gồm các bước thăm dò và họ sẽ tìm ra một chính sách tối ưu, có tính đến việc khám phá (exploration) vốn có trong chính sách.
"Q" ở đây là gì?
Chữ ‘Q’ trong Q-learning là viết tắt của "quality" chất lượng. Chất lượng ở đây thể hiện mức độ hữu ích của một hành động (action) nhất định trong việc đạt được một số phần thưởng (reward) trong tương lai.
Yếu tố chính của Q-learning
- Q*(s, a) là giá trị kỳ vọng (phần thưởng chiết khấu tích lũy) của việc thực hiện hành động (action) a ở trạng thái (state) s và sau đó tuân theo chính sách tối ưu (optimal policy).
- Q-learning sử dụng "Sự khác biệt theo thời gian" Temporal Differences (TD) để ước tính giá trị của Q*(s, a). TD là một chủ thể (agent) có khả năng học hỏi từ môi trường thông qua các giai đoạn (episodes) mà không có kiến thức trước về môi trường.
- Chủ thể (agent) duy trì một bảng Q[S, A], trong đó S là tập các trạng thái và A là tập các hành động.
- Q[s, s] đại diện cho ước tính hiện tại của nó là Q*(s, a).
Ví dụ
Giả sử một nhân viên phải di chuyển từ điểm bắt đầu đến điểm kết thúc dọc theo một con đường có chướng ngại vật. Nhiệm vụ cần đạt được tìm đường ngắn nhất có thể mà không va vào chướng ngại vật và anh ta cần đi theo ranh giới được che bởi chướng ngại vật.


Quy trình xử lý của thuật toán Q-learning

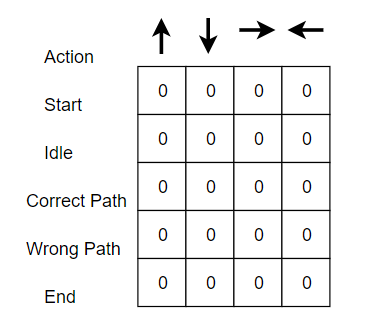
Bước 1: Khởi tạo Q-Table
Có n cột, trong đó n = số hành động (action). Có m hàng, trong đó m = số trạng thái (state).
Trong ví dụ của chúng ta, n = Đi trái, Đi phải, Đi lên và Đi xuống và m = "Bắt
đầu, Không hoạt động, Đường đúng, Đường sai và Kết thúc". Đầu tiên, hãy khởi tạo
các giá trị bằng các giá trị 0.
Bước 2: Chọn một hành
động
Bước 3: Thực hiện một hành động
Sự kết hợp của bước 2 và bước 3 được thực hiện trong một khoảng thời gian không xác định. Các bước này chạy cho đến khi quá trình huấn luyện thời gian bị dừng lại hoặc khi vòng lặp huấn luyện dừng lại như được xác định trong mã.
Đầu tiên, một action (a) hành động trong trạng thái state (s) được chọn dựa trên Q-Table. Lưu ý rằng, như đã đề cập trước đó, khi tập ban đầu bắt đầu, mọi giá trị Q phải bằng 0.
Sau đó, cập nhật các giá trị Q để ở đầu và di chuyển sang phải bằng cách sử dụng phương trình Bellman được nêu ở trên.
Khái niệm Epsilon greedy strategy xuất hiện ở đây. Trong thời gian đầu, tỷ lệ epsilon sẽ cao hơn. Chủ thể (agent) sẽ khám phá môi trường và lựa chọn ngẫu nhiên các hành động (action). Điều này xảy ra như thế này một cách hợp lý, vì agent không biết gì về môi trường. Khi agent tham dò môi trường, tỷ lệ epsilon giảm và agent bắt đầu khám phá môi trường.Trong quá trình thăm dò (exploration), agent dần dần tự tin hơn trong việc ước tính các giá trị Q.
Trong ví dụ, khi bắt đầu đào tạo agent của chúng ta, agent hoàn toàn không biết về môi trường. Vì vậy, giả sử nó thực hiện một hành động ngẫu nhiên theo hướng "phải" của nó.
Giờ đây, chúng tôi có thể cập nhật các giá trị Q ở thời điểm bắt đầu và chuyển động sang phải bằng cách sử dụng phương trình Bellman.


- Phần thưởng khi tiến gần hơn đến mục tiêu = +1
- Phần thưởng khi đạt chướng ngại vật = -1
- Phần thưởng khi nhàn rỗi = 0
Ban đầu, chúng ta khám phá môi trường của chủ thể (agent) và cập nhật Q-Table. Khi Q-Table đã sẵn sàng, agent bắt đầu khám phá môi trường và bắt đầu thực hiện các hành động tốt hơn. Q-Table cuối cùng có thể giống như sau (ví dụ).
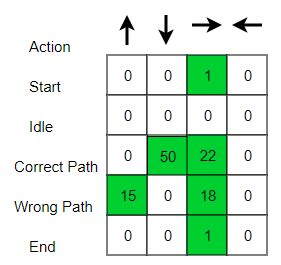
Sau đây là những kết quả dẫn đến con
đường ngắn nhất của nhân viên hướng tới mục tiêu sau khi đào tạo.


![[English] ex viết tắt của từ gì? ex là gì? ex nghĩa là gì?](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhFiRP7spsayG2ppte_20L5qkUrX_HsatNpN8LxoNux1ewEve0IUrCurRVh7VfOvFvrgvnfloMyf_KXZnWfif-BDKLlU5A9zSat0y-Bvu3BeNedpCEJsmMzBTZ-KVRFPfIUZZI60uG8Z5k/s72-c/what-is-ex-meaning.jpg)
![[VI ĐIỀU KHIỂN PIC] - BÀI 6: TIMER/COUNTER CỦA PIC TRONG CCS](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjCz787KDILJfZRV78M_FwKV1KfpbML6oDxg3VEpJgu0t0RJY02ANCf7h2BeqkgD5UgoufjwXLnxGh8Hj1RlBnjlkQYUBrrjUwObg3Ru4lGv0Slpmf1xEjvDJMp5sg425Oaoc_NCuUFqow/s72-c-d/pic-microcontrollers-examples-in-assembly-language-chapter-04-fig4-1.gif)
![[VI ĐIỀU KHIỂN PIC] - BÀI 7: ANALOG (ADC) CỦA PIC TRONG CCS](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiUKGTlRMrOPiQlrL-hvj4au7WA4MEdUChYe_L6bH5mOIDDBpmEBaW_oIKQYz04kfHKY2FmcWb8urcsZgPXMNp5r4ZHqskRjbYNp12JvklYcXHrnweaizv7lKPyribPyxWtsUNzggwXfOI/s72-c/04-06-2017+10-28-24+PM.png)
![[VI ĐIỀU KHIỂN PIC***] - BÀI TẬP MẪU ĐẶC BIỆT CỦA VI ĐIỀU KHIỂN PIC16F877A](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjeSJllTzabiuuA-Zd8LVZY9urJdd-InM0cVOkJtiqrwHcEGJQIajPm7BoERinwbHbEJ2fzFN_P49llQiqF-KyGMuY9NkP5HdA31GAcfcG4WjHdZl2RDngNbMNjts3gpkgib5sVR01eeKc/s72-c/1.png)
![[VI ĐIỀU KHIỂN PIC] - BÀI 9: KHỞI TẠO PWM TRONG PIC 16F877A VỚI CCS](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjerTKUiWHBBUrmBbbOQILAmqhC73Ubt_nYZR9fSu1FCPX2aXz59Ir4kJRIkpphvjOK_Aljt1NCDqHct6fmoeX8JomWvOu06OkZ7fYQvK975ftMf1J4kP8iYpX6P9tPo3NmiSXTS_vUjRY/s72-c/10-06-2017+11-40-42+PM.png)

![[VI ĐIỀU KHIỂN PIC] - BÀI 8: GIAO TIẾP LM35 PIC16F877A TRONG CCS](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgf6kgYQjVzdLTbPiEhjagyXQbubtwplknQ3H2kdg-7T6Di-5_oIpvAGdP3W4DL9sKeSUktz35CKibzHAz7j0eZI5sp1kGnbTYT5bBoy0P7Xv-RPxmUC_SXC9FkrCXS4Kdc3Ob1E7cI0eI/s72-c/HH.png)
![[Research] Cách viết và cấu trúc chi tiết một bài báo khoa học](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiK5FSwIEKPC-QCKmUI_fsFHf3mhlU4GnKEgYQ5vo6SnFVhgOb9iR4_1pCRXk8kuKCQuh9m8xZGH8nDQGO-gsAq5IhT1t5wpHfN3iTLtN45k1UeNG36d1QhMPHPLgpJQntMRPIjb2vwI-0/s72-c/Picture5.jpg)